
Migros betreibt verschiedene Websites und eine App, die alle Produktdaten anzeigen müssen. Wir haben die M-API entwickelt – eine Symfony-Anwendung, welche die Daten aus den verschiedenen Systemen sammelt, bereinigt und mit Elasticsearch indexiert. Dieser Index kann in Echtzeit über eine REST-API abgefragt werden, die JSON- und XML-Ausgaben unterstützt. Die M-API verarbeitet mehrere Millionen Anfragen pro Tag und funktioniert auch bei maximaler Auslastung zuverlässig.
API-Architektur
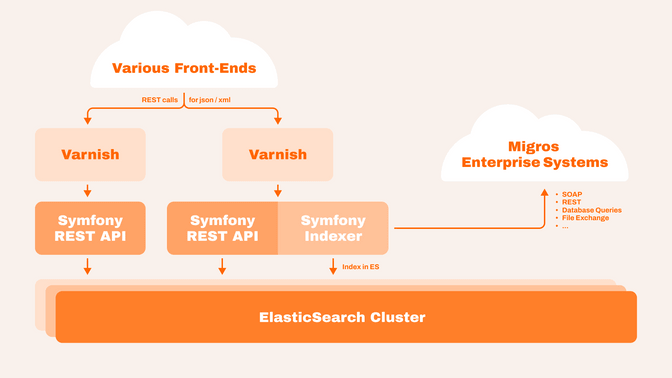
Die Dokumente in Elasticsearch sind gross und enthalten viele verschachtelte Daten. Um die Abfragen schneller zu machen, haben wir alle produktbezogenen Daten denormalisiert und direkt in jedes Produktdokument integriert. Wenn sich ein Teil der Produktinformationen ändert, bauen wir die Daten neu auf und indexieren das Produkt erneut. Die API bietet Abfrageparameter, um zu steuern, wie viele Details in der Antwort enthalten sein sollen.
Die Symfony-Anwendung basiert auf Domain-Model-Klassen für die Daten. Beim Indexieren werden die Modelle mit Daten aus externen Systemen gefüllt und in Elasticsearch gespeichert. Beim Abfragen werden die Modelle aus Elasticsearch-Antworten wiederhergestellt und in das gewünschte Format sowie mit dem angeforderten Detaillierungsgrad serialisiert.
Wir nutzen den JMS-Serializer, weil er Felder gruppieren kann, um die Detailtiefe zu steuern und sogar mehrere API-Versionen aus derselben Datenquelle unterstützt. Zur Leistungssteigerung haben wir einen eigenen Serializer für JMS geschrieben.
Natürlich gibt es einen gewissen Overhead, da die Elasticsearch-Daten ent- und wieder serialisiert werden müssen. Doch die gewonnene Flexibilität überwiegt diesen Nachteil.
Vor der M-API setzen wir Varnish-Server ein, um Antworten zu cachen. Wir nutzen das FOSHttpCacheBundle, um Caching-Header zu verwalten und zwischengespeicherte Daten bei Bedarf zu invalidieren.
Eine eigenständige API
Die M-API ist eine separate Symfony-Anwendung und bietet keine HTML-Darstellung. Ihre einzige Aufgabe ist das Sammeln, Normalisieren und Indexieren von Daten sowie deren Bereitstellung über eine REST-API. Dies ermöglicht eine Multi-Channel-Strategie.
Auf der M-API basierende Systeme umfassen eine Produktkatalog-Website, eine mobile App, eine Kundenplattform und verschiedene Marketingseiten für spezifische Produktgruppen. Jede dieser Plattformen kann unabhängig entwickelt werden, auch mit anderen Technologien als PHP. Während der Produktkatalog als Symfony-Anwendung umgesetzt wurde, ist die Mobile App eine native iOS- und Android-Anwendung, und viele Marketing-Websites nutzen das Java-basierte CMS Magnolia.

Dank der M-API können solche Webanwendungen sich auf ihre eigentlichen Use Cases konzentrieren und die Daten einfach abrufen, statt selbst Importmechanismen aus verschiedenen Quellen zu entwickeln. Dies spart Zeit und Aufwand. Zudem verbessert sich auch die Datenqualität, da Korrekturen zentral in der M-API vorgenommen werden.
Die Datensammlung ist komplex. Die M-API erfasst:
- Kern-Produktdaten aus dem zentralen Produktkatalog und Preissystemen
- Bilder, die für das Web über das CDN rokka.io aufbereitet werden
- Meta-Daten wie chemische Warnhinweise oder Produktempfehlungen aus Data-Warehouse-Analysen
- Bestandsinformationen aus dem Lagerverwaltungssystem sowie eine Filialsuche
- Beliebtheitsdaten basierend auf Kundenfeedback und Google Analytics
Entwicklungsprozess
Zusammen mit dem Kunden haben wir einen agilen Entwicklungsprozess gewählt.
Das Minimalprodukt war eine API, die Produktdaten in JSON und XML bereitstellt. Nach einigen Monaten hatte die API genügend Funktionalität und wurde live geschaltet. In den letzten 10 Jahren haben wir kontinuierlich neue Datenquellen und API-Endpunkte hinzugefügt und alle zwei Wochen neue Releases veröffentlicht.
Um die API stabil zu halten, haben wir Versionierung eingeführt. Jede Anfrage muss einen Version-Header enthalten, damit API-Konsument*innen in ihrem eigenen Tempo aktualisieren können. Mit dem JMS-Serializer konnten wir alte API-Versionen dynamisch unterstützen, ohne Daten zu duplizieren. Wir führten auch einen Changelog ein, um Kund*innen bei Upgrades zu unterstützen.
Um die gleiche Code-Base auf Test- und Produktivsystemen auszuführen, ohne Features zu früh auszurollen, nutzten wir Feature Flags.
Indexierungsarchitektur
Beim Indexieren denormalisieren wir viele Daten, um schnelle Abfragen zu ermöglichen. Beispielsweise speichern wir den gesamten Produktkategorie-Breadcrumb direkt im Produkt, damit eine einzige Elasticsearch-Anfrage reicht. Da während des Indexierens viele Daten benötigt werden, kopieren wir langsam abfragbare Daten in ein lokales MySQL-Cache-System. Redis dient zusätzlich als Zwischenspeicher für eine noch schnellere Verarbeitung.
Die Haupt-Datenimporte laufen als Symfony-Commands, die die MySQL-Datenbank mit aktuellen Daten aktualisieren. Diese Prozesse werden parallelisiert mit RabbitMQ-Worker.
Eine Herausforderung war die Neuerstellung des Elasticsearch-Indexes bei Schema-Änderungen. Da der Index mehrere Hunderttausend Dokumente umfasst, dauert das Re-Indexieren lange.
Um das zu optimieren:
- Neuer Code wird ausgerollt, ohne online zu gehen
- Ein neuer Index wird erstellt, indem Dokumente aus dem alten Index kopiert werden (schneller als ein kompletter Re-Import)
- Nach Fertigstellung wird der neue Index aktiv geschaltet
Diese Strategie spart Zeit und Systemressourcen.
When a schema change occurs, we first deploy the code to the servers without bringing it online, build a new index and, once the new index is ready, switch web requests to the new deployment. The new index is built by copying the documents from the old index, which is a lot faster and puts less strain on the system than re-indexing everything from MySQL.