

You'll take a coaster and start calculating quickly. All factors need to be taken into account as you write down your calculations on the edge of the coaster. Once your coaster is full, you'll know a lot of answers to a lot of questions: How much can I offer for this piece of land? How expensive will one flat be? How many parking lots could be built and how expensive are they? And of course there's many more.
In the beginning, there was theory
Architecture students at the ETH learn this so-called "coaster method" in real estate economics classes. Planning and building a house of any size is no easy task to begin with, and neither is understanding the financial aspect of it. To understand all of those calculations, some students created spreadsheets that do the calculations for them. This is prone to error. There are many questions that can be answered and many parameters that influence those answers. The ETH IÖ app was designed to teach students about the complex correlations of different factors that influence the decision. Furthermore, if building a house on a certain lot is financially feasible or not.
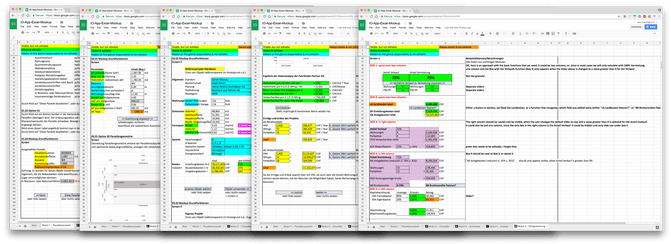
The product owner at ETH, a lecturer for real estate economics, took the tome to create such speadsheets, much like the students. These spreadsheets contained all calculations and formulas that were part of the course, as well as some sample calculations. After a thorough analysis of the spreadsheet, we came up with a total of about 60 standalone values that could be adjusted by the user, as well as about 45 subsequent formulas that used those values and other formulas to yield yet another value.
60 values and 45 subsequent formulas, all of them calculated on a coaster. Implementing this over several components would end up in a mess. We needed to abstract this away somehow.
Exploring the technologies
The framework we chose to build the frontend application with, was Vue. We used Vue to build a prototype already. so we figured we could reuse some components. We already valued Vue's size and flexibility and were somewhat familiar with it, so it was a natural choice. There's two main possibilities of handling your data when working with Vue: Either manage state in the components, or in a state machine, like Vuex.
Since many of the values need to be either changed or displayed in different components, keeping the state on a component level would tightly couple those components. This is exactly what is happening in the spreadsheet mentioned earlier. Fields from different parts of the sheet are referenced directly, making it hard to retrace the path of the data.
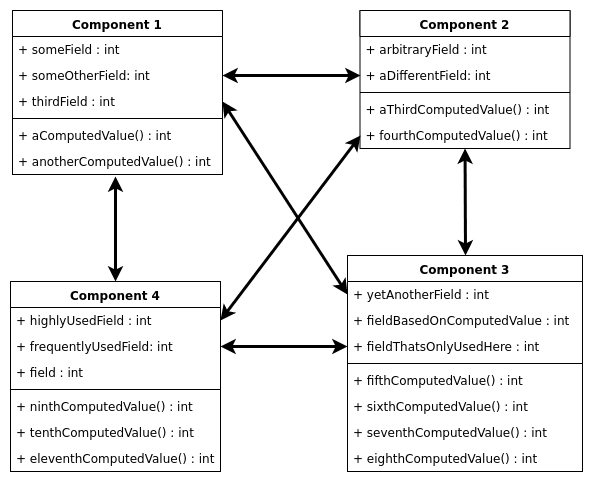
Keeping the state outside of the components and providing ways to update the state from any component decouples them. Not a single calculation needs to be done in an otherwise very view-related component. Any component can trigger an update, any component can read, but ultimately, the state machine decides what happens with the data.
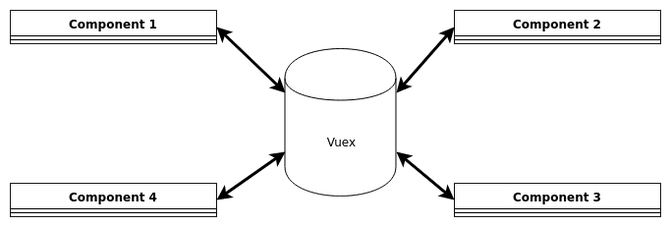
Vue has a solution for that: Vuex. Vuex allows to decouple the state from components, moving them over to dedicated modules. Vue components can commit mutations to the state or dispatch actions that contain logic. For a clean setup, we went with Vuex.
Building the Vuex modules
The core functionality of the app can be boiled down to five steps:
- Find the lot - Where do I want to build?
- Define the building - How large is it? How many floors, etc.?
- Further define any building parameters and choose a reference project - How many flats, parking lots, size of a flat?
- Get the standards - What are the usual prices for flats and parking lots in this region?
- Monetizing - What's the net yield of the building? How can it be influenced?
Those five steps essential boil down to four different topics:
- The lot
- The building with all its parameters
- The reference project
- The monetizing part
These topics can be treated as Vuex modules directly. An example for a basic module Lot would look like the the following:
// modules/Lot/index.js
export default {
// Namespaced, so any mutations and actions can be accessed via `Lot/...`
namespaced: true,
// The actual state: All fields that the lot needs to know about
state: {
lotSize: 0.0,
coefficientOfUtilization: 1.0,
increasedUtilization: false,
parkingReductionZone: 'U',
// ...
}
}The fields within the state are some sort of interface: Those are the fields that can be altered via mutations or actions. They can be considered a "starting point" of all subsequent calculations.
Those subsequent calculations were implemented as getters within the same module, as long as they are still related to the Lot:
// modules/Lot/index.js
export default {
namespaced: true,
state: {
lotSize: 0.0,
coefficientOfUtilization: 1.0
},
// Getters - the subsequent calculations
getters: {
/**
* Unit: m²
* DE: Theoretisch realisierbare aGF
* @param state
* @return {number}
*/
theoreticalRealizableCountableFloorArea: state => {
return state.lotSize * state.coefficientOfUtilization
},
// ...
}
}And we're good to go. Mutations and actions are implemented in their respective store module too. This makes the part of the data actually changing more obvious.
Benefits and drawbacks
With this setup, we've achieved several things. First of all, we separated the data from the view, following the "separation of concerns" design principle. We also managed to group related fields and formulas together in a domain-driven way, thus making their location more predictable. All of the subsequent formulas are now also unit-testable. Testing their implementation within Vue components is harder as they are tightly coupled to the view. Thanks to the mutation history provided by the Vue dev tools, every change to the data is traceable. The overall state of the application also becomes exportable, allowing for an easier implementation of a "save & load" feature. Also, reactivity is kept as a core feature of the app - Vuex is fast enough to make any subsequent update of data virtually instant.
However, as with every architecture, there's also drawbacks. Mainly, by introducing Vuex, the application is getting more complex in general. Hooking the data to the components requires a lot of boilerplating - otherwise it's not clear which component is using which field. As all the store modules need similar methods (f.e. loading data or resetting the entire module) there's also a lot of boilerplating going on. Store modules are tightly coupled with each other by using fields and getters of basically all modules.
In conclusion, the benefits of this architecture outweigh the drawbacks. Having a state machine in this kind of application makes sense.
Takeaway thoughts
The journey from the coasters, to the spreadsheets, to a whiteboard, to an actual usable application was thrilling. The chosen architecture allowed us to keep a consistent set up, even with growing complexity of the calculations in the back. The app became more testable. The Vue components don't even care anymore about where the data is from, or what happens with changed fields. Separating the view and the model was a necessary decision to avoid a mess and tightly coupled components - the app stayed maintainable, which is important. After all, the students are using it all the time.