

Estimated reading time: < 5 minutes. Target audience: developers and product owners.
First, a word about software development
Over time, every software goes into maintenance; minor features might get developed, bugs are fixed and frameworks get upgraded to their latest versions. One of the potential side effect of this activity is "regression". Something that used to work suddenly doesn't anymore. The most common way to prevent this is writing tests and running them automatically on every changes. So everytime a new feature is developed or a bug fixed, a piece of code is written to ensure that the application will, from that moment on, work as expected. And if some changes break the application, the failing tests should prevent them from being released.
In practice however, it happens more often than not, that tests get overlooked... That's where it all started.
The situation
We maintain an application built with Symfony. It provides an API for which some automated tests were written, when it was first implemented years ago. But even though the application kept evolving as the years went by (and its API started being used by more and more third-party applications), the number of tests remained unchanged. This slowly created a tension, as the importance of the API's stability increased (as more applications depended on it) and the tests coverage decreased (as new features were developed and no tests were written for them).
The solution that first came to mind
Facing this situation, my initial thoughts went something like this :
We should review every API-related test, evaluate their coverage and complete them if needed!
We should review every API endpoint to find those that are not yet covered by tests and add them!
That felt like an exhaustive and complete solution; one I could be proud of once delivered. My enthusiasm was high, because it triggered something dear to my heart, as my quest to leave the code cleaner than I found it was set in motion (also known as the "boy-scout rule"). If this drive for quality had been my sole constraint, that's probably the path I would have chosen — the complex path.
Here, however, the project's budget did not allow to undertake such an effort. Which was a great opportunity to...
Gain another perspective
As improving the test suite was out of the picture, the question slowly shifted to :
What could bring more confidence and trust to the developers that the API will remain stable on the long run, when changes in the code will inevitably occur?
Well, "changes" is still a little vague here to answer the question, so let's get more specific :
- If a developer changes something in the project related to the API, I trust that he will test the feature he changed; there's not much risk involved in that scenario. But...
- If a developer changes something in the project that has nothing to do with the API and yet the change may break it, this is trouble !
The biggest risk I've identified to break the API inadvertently, by applying (seemingly) unrelated changes and not noticing it, lies in the Symfony Routing component, used to define API's endpoints :
- Routes can override each other if they have the same path, and the order in which they are added to the configuration files matters. Someone could add a new route with a path identical to an existing API endpoint's one and break the latter.
- Upgrading to the next major version of Symfony may lead to mandatory changes in the way routes are defined (it happened already), which opens up the door to human errors (forgetting to update a route's definition for example).
- Routes' definitions are located in other files and folders than the code they're related to, which makes it hard for the developer to be conscious of their relationship.
All of this brings fragility. So I decided to focus on that, taking a "Minimum Viable Product" approach that would satisfy the budget constraint too.
Symfony may be part of the problem, but it can also be part of the solution. If the risk comes from changes in the routing, why not use Symfony's tools to monitor them ?
The actual implementation (where it gets technical)
The command debug:router lists all the routes' definitions defined in a Symfony application. There's also a --format argument that allows to get the output as JSON, which is perfect to write a script that relies on that data.
As for many projects at Liip, we use RMT to release new versions of the application. This tool allows for "prerequisites" scripts to be executed before any release is attempted : useful to run a test suite or, in this case, to check if the application's routing underwent any risky changes.
The first requisite for our script to work is to have a reference point. We need a set of the routes' definitions in a "known stable state". This can be done by running the following command on the master branch of the project, for example:
bin/console debug:router --format=json > some_path/routing_stable_dump.jsonThen it could go something like this :
- Use the Process Component to run the
bin/console debug:router --format=jsoncommand, pass the output tojson_decode(), store it in a variable (that's the new routing). - Fetch the reference point using
file_get_contents(), pass the output tojson_decode(), store it in a variable (that's the stable routing). - Compare the two variables. I used swaggest/json-diff to create a diff between the two datasets.
- Evaluate if the changes are risky or not (depending on the business' logic) and alert the developer if they are (and prevent the release).
Here's an example of output from our script :
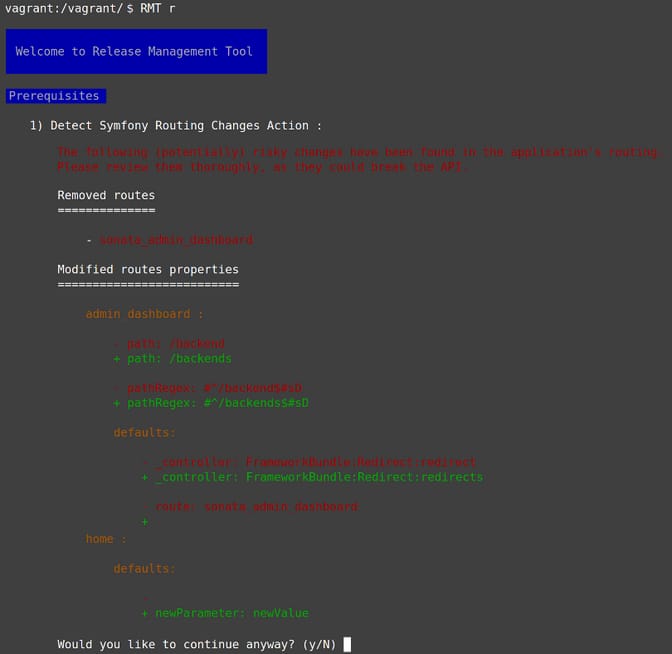
Closing thoughts
I've actually had a great time implementing this script and do feel proud of the work I did. And besides, I'm quite confident that the solution, while not perfect, will be sufficient to increase the peace of mind of the project's developers and product owners.
What do you think? Would you have an another approach? I'd love to read all about it in the comments.