
As you maybe know, we use Jackrabbit for some of our projects and plan to use it even more. I personally still like the idea of it and until now it did what it promised.
One thing ‘though I never really like is the dependency on one single “persistent store” where everything is stored and read from. Of course you can make that pretty high-available and it will scale well (jackrabbit usually has the bottlenecks somewhere else than in the persistent storage, but there it can easily scale with clustering). But still, knowing that your solution has one single-point-of-bottleneck you can't get away from even for read only operations made me somehow uneasy. Additionally regional scale out (serve from regionally totally different and independent data centers for faster responses and additional fail-safyness. Since we all know now, even highly reliable DCs can go down) is almost impossible, at least if you don't want your frontend servers to have to connect back to the home-datacenter all the time and produce a lot of traffic between your DCs.
The clustering of Jackrabbit is pretty decent and well thought out. You can write on any of your jackrabbit instances and don't have the master-slave scenario as with eg. MySQL. They sync with each other pretty fast and all is well. Clustering in Jackrabbit works with a so called Journal, where all the instances write their changes into and the other instances read from to know what changed and update their index and caches. They also write their current position of the journal into that database.
With this setup, the first thing which came to my mind for scale-out was to setup MySQL replication where the slave is in a different DC and read-only jackrabbit instances [1] read the content data from that slave, but write their journal info to the database of the master mysql in the 1st DC. This is already possible with the current Jackrabbit releases, as you can define different databases for the persistence manager and the clustering journal.
The one problem with that is that MySQL replication is asynchron and always has a lag. So if one of those read-only jackrabbits reads the journal data from the master database, the actual content may not be already in the slave and can't be read therefore, which can lead to nasty situations. The solution to this problem seemed to be to read the journal data also from the slave, but write to the master, so we can be sure, that everything is synced to the slave.
Digging into the source code of jackrabbit revealed that this is quite an easy task and this patch should do the job. It also saves some traffic between the DCs, since now the check if something changed (which happens every few seconds) stays in the same DC and not between different DCs as before.
Some tests showed that it actually works, even if you turn off the master MySQL or the replication. After they come up, it happily replicates and syncs again. And if you have a catastrophic failure in the 1st DC, you just switch the MySQL slave to be the master and define the jackrabbits in the 2nd DC as the new read-write instances and you can continue. The traffic between the DCs will only be the mysql replication traffic. Depending on how much content updates you have, that won't be much.
And here's the obligatory graph to show this setup visually more appealing:
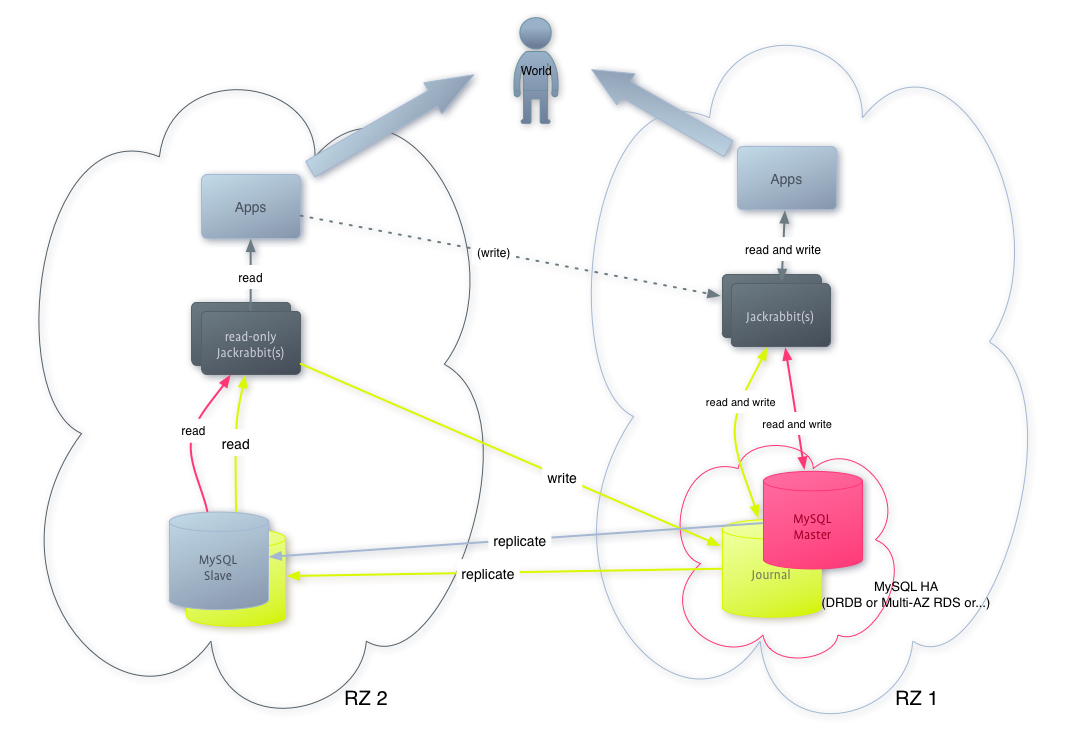
To sum up: The goal was reached with this setup that we can scale out almost indefinitely and over globally distributed data centers without having too much traffic between them. And in case the “master” DC fails, we can switch pretty fast to another one.
[1] Read-Only jackrabbits, because in a MySQL master-slave setup you can not write to slaves, but for our purpose, read-only jackrabbits in secondary DCs are enough, since we just want to serve content from there for scale-out purposes, or if the 1st DC fails. We won't have too many write operations in those 2nd DCs (during normal operations) so the few we will have (eg. for comments) will be redirected to a jackrabbit instance in the 1st DC. Handling that in jackrabbit itself (reading from one source, writing to the other) seemed to be too complicated to implement.