

Overview SaaS
When it comes to sentiment detection it has become a bit of a commodity. Especially the big 5 vendors offer their own sentiment detection as a service. Google offers an NLP API with sentiment detection. Microsoft offers sentiment detection through their Azure platform. IBM has come up with a solution called Tone Analyzer, that tries to get the "tone" of the message, which goes a bit beyond sentiment detection. Amazon offers a solution called comprehend that runs on aws as a lambda. Facebook surprisingly doesn't offer an API or an open source project here, although they are the ones with user generated content, where people often are not so nice to each other. Interestingly they do not offer any assistance for page owners in that specific matter.
Beyond the big 5 there are a few noteworthy of companies like Aylien and Monkeylearn, that are worth checking out.
Overview Open Source Solutions
Of course there are are open source solutions or libraries that offer sentiment detection too.
Generally all of these tools offer more than just sentiment analysis. Most of the outlined SaaS solutions above as well as the open source libraries offer a vast amount of different NLP tasks:
- part of speech tagging (e.g. "going" is a verb),
- stemming (finding the "root" of a word e.g. am,are,is -> be),
- noun phrase extraction (e.g. car is a noun),
- tokenization (e.g. splitting text into words, sentences),
- words inflections (e.g. what's the plural of atlas),
- spelling correction and translation.
I like to point you to pythons NLTK library, TextBlob, Pattern or R's Text Mining module and Java's LingPipe library. Finally, I encourage you to have a look at the latest Spacy NLP suite, which doesn't offer sentiment detection per se but has great NLP capabilities.
If you are looking for more options I encourage you to take a look at the full list that I have compiled in our data science stack.
Let's get started
So you see, when you need sentiment analysis in your web-app or mobile app you already have a myriad of options to get started. Of course you might build something by yourself if your language is not supported or you have other legal compliances to meet when it comes to data privacy.
Let me walk you through all of the steps needed to make a well working sentiment detection with Keras and long short-term memory networks. Keras is a very popular python deep learning library, similar to TFlearn that allows to create neural networks without writing too much boiler plate code. LSTM networks are a special form or network architecture especially useful for text tasks which I am going to explain later.

Step 1: Get the data
Being a big movie nerd, I have chosen to classify IMDB reviews as positive or negative for this example. As a benefit the IMDB sample comes already with the Keras datasets library, so you don't have to download anything. If you are interested though, not a lot of people know that IMDB offers its own datasets which can be downloaded publicly. Among those we are interested in the ones that contain movie reviews, which have been marked by hand to be either positive or negative.
#download the data
from keras.datasets import imdb
top_words = 5000
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=top_words)The code above does a couple of things at once:
- It downloads the data
- It downloads the first 5000 top words for each review
- It splits the data into a test and a training set.
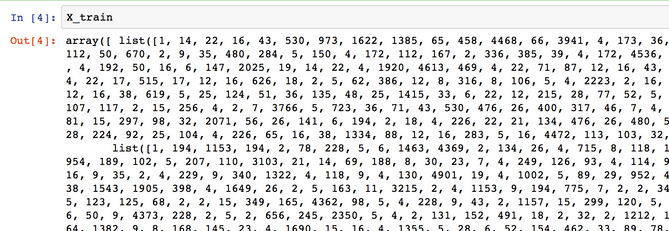
If you look at the data you will realize it has been already pre-processed. All words have been mapped to integers and the integers represent the words sorted by their frequency. This is very common in text analysis to represent a dataset like this. So 4 represents the 4th most used word, 5 the 5th most used word and so on... The integer 1 is reserved reserved for the start marker, the integer 2 for an unknown word and 0 for padding.
If you want to peek at the reviews yourself and see what people have actually written, you can reverse the process too:
#reverse lookup
word_to_id = keras.datasets.imdb.get_word_index()
word_to_id = {k:(v+INDEX_FROM) for k,v in word_to_id.items()}
word_to_id["<PAD>"] = 0
word_to_id["<START>"] = 1
word_to_id["<UNK>"] = 2
id_to_word = {value:key for key,value in word_to_id.items()}
print(' '.join(id_to_word[id] for id in train_x[0] ))The output might look like something like this:
<START> this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert <UNK> is an amazing actor and now the same being director <UNK> father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for <UNK> and would recommend it to everyone to watch and the fly <UNK> was amazing really cried at the end it was so sad and you know wOne-hot encoder
If you want to do the same with your text (e.g. my example are some work reviews) you can use Keras already built in "one-hot" encoder feature that will allow you to encode your documents with integers. The method is quite useful since it will remove any extra marks (e.g. !"#$%&...) and split sentences into words by space and transform the words into lowercase.
#one hot encode your documents
from numpy import array
from keras.preprocessing.text import one_hot
docs = ['Gut gemacht',
'Gute arbeit',
'Super idee',
'Perfekt erledigt',
'exzellent',
'naja',
'Schwache arbeit.',
'Nicht gut',
'Miese arbeit.',
'Hätte es besser machen können.']
# integer encode the documents
vocab_size = 50
encoded_docs = [one_hot(d, vocab_size) for d in docs]
print(encoded_docs)Although the encoding will not be sorted like in our example before (e.g. lower numbers representing more frequent words), this will still give you a similar output:
[[18, 6], [35, 39], [49, 46], [41, 39], [25], [16], [11, 39], [6, 18], [21, 39], [15, 23, 19, 41, 25]]Step 2: Preprocess the data
Since the reviews differ heavily in terms of lengths we want to trim each review to its first 500 words. We need to have text samples of the same length in order to feed them into our neural network. If reviews are shorter than 500 words we will pad them with zeros. Keras being super nice, offers a set of preprocessing routines that can do this for us easily.
# Truncate and pad the review sequences
from keras.preprocessing import sequence
max_review_length = 500
X_train = sequence.pad_sequences(X_train, maxlen=max_review_length)
X_test = sequence.pad_sequences(X_test, maxlen=max_review_length) 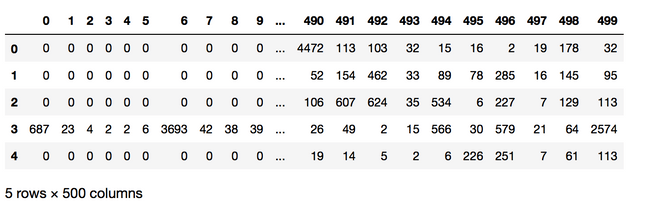
As you see above (I've just output the padded Array as a pandas dataframe for visibility) a lot of the reviews have padded 0 at the front which means, that the review is shorter than 500 words.
Step 3: Build the model
Surprisingly we are already done with the data preparation and can already start to build our model.
# Build the model
embedding_vector_length = 32
model = Sequential()
model.add(Embedding(top_words, embedding_vector_length, input_length=max_review_length))
model.add(LSTM(100))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',optimizer='adam', metrics=['accuracy'])
print(model.summary()) The two most important things in our code are the following:
- The Embedding layer and
- The LSTM Layer.
Lets cover what both are doing.
Word embeddings
The embedding layer will learn a word embedding for all the words in the dataset. It has three arguments the input_dimension in our case the 500 words. The output dimension aka the vector space in which words will be embedded. In our case we have chosen 32 dimensions so a vector of the length of 32 to hold our word coordinates.
There are already pre-trained word embeddings (e.g. GloVE or Word2Vec) that you can download so that you don't have to train your embeddings all by yourself. Generally, these word embeddings are also based on specialized algorithms that do the embedding always a bit different, but we won't cover it here.
How can you imagine what an embedding actually is? Well generally words that have a similar meaning in the context should be embedded next to each other. Below is an example of word embeddings in a two-dimensional space:
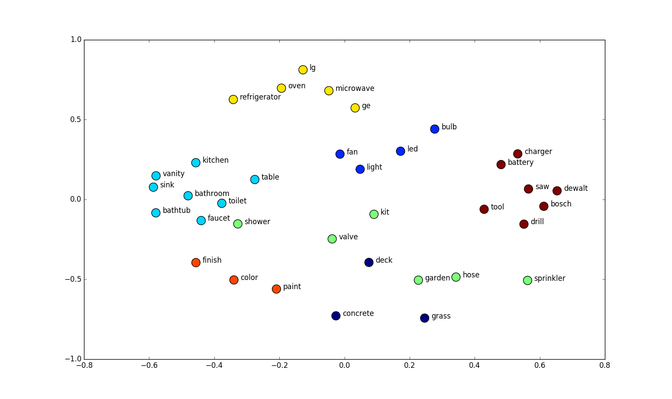
Why should we even care about word embeddings? Because it is a really useful trick. If we were to feed our reviews into a neural network and just one-hot encode them we would have very sparse representations of our texts. Why? Let us have a look at the sentence "I do my job" in "bag of words" representation with a vocabulary of 1000: So a matrix that holds 1000 words (each column is one word), has four ones in it (one for I, one for do one for my and one for job) and 996 zeros. So it would be very sparse. This means that learning from it would be difficult, because we would need 1000 input neurons each representing the occurrence of a word in our sentence.
In contrast if we do a word embedding we can fold these 1000 words in just as many dimensions as we want, in our case 32. This means that we just have an input vector of 32 values instead of 1000. So the word "I" would be some vector with values (0.4,0.5,0.2,...) and the same would happen with the other words. With word embedding like this, we just need 32 input neurons.
LSTMs
Recurrent neural networks are networks that are used for "things" that happen recurrently so one thing after the other (e.g. time series, but also words). Long Short-Term Memory networks (LSTM) are a specific type of Recurrent Neural Network (RNN) that are capable of learning the relationships between elements in an input sequence. In our case the elements are words. So our next layer is an LSTM layer with 100 memory units.
LSTM networks maintain a state, and so overcome the problem of a vanishing gradient problem in recurrent neural networks (basically the problem that when you make a network deep enough the information for learning will "vanish" at some point). I do not want to go into detail how they actually work, but here delivers a great visual explanation. Below is a schematic overview over the building blocks of LSTMs.
So our output of the embedding layer is a 500 times 32 matrix. Each word is represented through its position in those 32 dimensions. And the sequence is the 500 words that we feed into the LSTM network.
Finally at the end we have a dense layer with one node with a sigmoid activation as the output.
Since we are going to have only the decision when the review is positive or negative we will use binary_crossentropy for the loss function. The optimizer is the standard one (adam) and the metrics are also the standard accuracy metric.
By the way, if you want you can build a sentiment analysis without LSTMs, then you simply need to replace it by a flatten layer:
#Replace LSTM by a flatten layer
#model.add(LSTM(100))
model.add(Flatten()) Step 4: Train the model
After defining the model Keras gives us a summary of what we have built. It looks like this:
#Summary from Keras
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 500, 32) 160000
_________________________________________________________________
lstm_1 (LSTM) (None, 100) 53200
_________________________________________________________________
dense_1 (Dense) (None, 1) 101
=================================================================
Total params: 213,301
Trainable params: 213,301
Non-trainable params: 0
_________________________________________________________________
NoneTo train the model we simply call the fit function,supply it with the training data and also tell it which data it can use for validation. That is really useful because we have everything in one call.
#Train the model
model.fit(X_train, y_train, validation_data=(X_test, y_test), nb_epoch=3, batch_size=64) The training of the model might take a while, especially when you are only running it on the CPU instead of the GPU. When the model training happens, what you want to observe is the loss function, it should constantly be going down, this shows that the model is improving. We will make the model see the dataset 3 times, defined by the epochs parameter. The batch size defines how many samples the model will see at once - in our case 64 reviews.

To observe the training you can fire up tensor board which will run in the browser and give you a lot of different analytics, especially the loss curve in real time. To do so type in your console:
sudo tensorboard --logdir=/tmpStep 5: Test the model
Once we have finished training the model we can easily test its accuracy. Keras provides a very handy function to do that:
#Evaluate the model
scores = model.evaluate(X_test, y_test, verbose=0)
print("Accuracy: %.2f%%" % (scores[1]*100))In our case the model achieved an accuracy of around 90% which is excellent, given the difficult task. By the way if you are wondering what the results would have been with the Flatten layer it is also around 90%. So in this case I would use Occam's razor and in case and in doubt: go with the simpler model.
Step 6: Predict something
Of course at the end we want to use our model in an application. So we want to use it to create predictions. In order to do so we need to translate our sentence into the corresponding word integers and then pad it to match our data. We can then feed it into our model and see if how it thinks we liked or disliked the movie.
#predict sentiment from reviews
bad = "this movie was terrible and bad"
good = "i really liked the movie and had fun"
for review in [good,bad]:
tmp = []
for word in review.split(" "):
tmp.append(word_to_id[word])
tmp_padded = sequence.pad_sequences([tmp], maxlen=max_review_length)
print("%s. Sentiment: %s" % (review,model.predict(array([tmp_padded][0]))[0][0]))
i really liked the movie and had fun. Sentiment: 0.715537
this movie was terrible and bad. Sentiment: 0.0353295In this case a value close to 0 means the sentiment was negative and a value close to 1 means its a positive review. You can also use "model.predict_classes" to just get the classes of positive and negative.
Conclusion or what’s next?
So we have built quite a cool sentiment analysis for IMDB reviews that predicts if a movie review is positive or negative with 90% accuracy. With this we are already quite close to industry standards. This means that in comparison to a quick prototype that a colleague of mine built a few years ago we could potentially improve on it now. The big benefit while comparing our self-built solution with an SaaS solution on the market is that we own our data and model. We can now deploy this model on our own infrastructure and use it as often as we like. Google or Amazon never get to see sensitive customer data, which might be relevant for certain business cases. We can train it with German or even Swiss German language given that we find a nice dataset, or simply build one ourselves.
As always I am looking forward to your comments and insights! As usual you can download the Ipython notebook with the code here.
P.S. The people from monkeylearn contacted me and pointed out that they have written quite an extensive introduction to sentiment detection here: https://monkeylearn.com/sentiment-analysis/ so I point you to that in case you want to read up on the general concepts.