

More than one year ago I sat down and went through my various github stars and browser bookmarks to compile what I then called the Data Science stack. It was basically an exhaustive collection of tools from which some I use on a daily basis, while others I have only heard of. The outcome was a big PDF poster which you can download here.
The good thing about it was, that every tool I had in mind could be found there somewhere, and like a map I could instantly see to which category it belonged. As a bonus I was able to identify my personal white spots on the map. The bad thing about it was, that as soon as I have compiled the list, it was out of date. So I transferred the collection into a google sheet and whenever a new tool emerged on my horizon I added it there. Since then - in almost a year - I have added over 102 tools to it.
From PDF to Data Science Stack website
While it would be OK to release another PDF of the stack year after year, I thought that might be a better idea to turn this into website, where everybody can add tools to it.
So without further ado I present you the http://datasciencestack.liip.ch page. Its goal is still to provide an orientation like the PDF, but eventually never become stale.

Adding Tools: Adding tools to my google sheet felt a bit lonesome, so I asked others internally to add tools whenever they find new ones too. Finally when moving away from the old google sheet and opening our collection process to everybody I have added a little button on the website that allows everybody to add tools by themselves to the appropriate category. Just send us the name, link and a quick description and we will add it there after a quick sanity check. The goal is to gather user generated input too! The I am thinking also about turning the website into a “github awesome” repository, so that adding tools can be done more in a programmer friendly way.
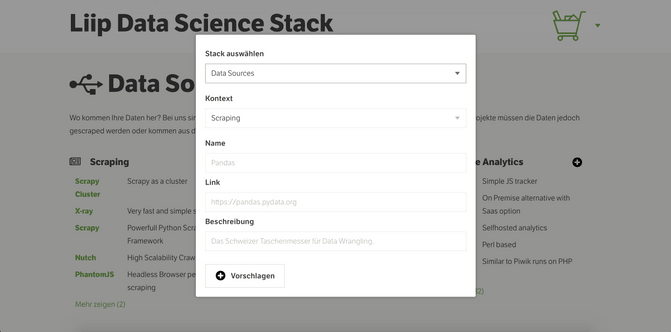
Search: When entering new tools, I realized that I was not sure if that tool already exists on the page, and since tools are hidden away after the first five the CTRL+F approach didn’t really work. That's why the website now has a little search box to search if a tool is already in our list. If not just add it to the appropriate category.
Mailing List: If you are a busy person and want to stay on top of things, I would not expect you to regularly check back and search for changed entries. This is why I decided to send out a quarterly mailing that contains the new tools we have added since our last data science stack update. This helps you to quickly reconnect to this important topic and maybe also to discover a data science gem you have not heard of yet.
JSON download: Some people asked me for the raw data of the PDF and at that time I was not able to give it to them quickly enough. That's why I added a json route that allows you to simply download the whole collection as a json file and create your own visualizations / maps or stacks with the tools that we have collected. Maybe something cool is going to come out of this.
Communication: Scanning through such a big list of options can sometimes feel a bit overwhelming, especially since we don’t really provide any additional info or orientation on the site. That’s why I added multiple ways of contacting us, in case you are just right now searching for a solution for your business. I took the liberty to also link our blog posts that are tagged with machine learning at the bottom of the page, because often we make use of the tools in these.
Zebra integration: Although it's nowhere visible on the website, I have hooked up the data science stack to our internal “technology database” system, called Zebra (actually Zebra does a lot more, but for us the technology part is relevant). Whenever someone enters a new technology into our technology db, it is automatically added for review to the data science stack. Like this we are basically tapping into the collective knowledge of all of our employees our company. A screenshot below gives a glimpse of our tech db on zebra capturing not only the tool itself but also the common feelings towards it.
Insights from collecting tools for one more year
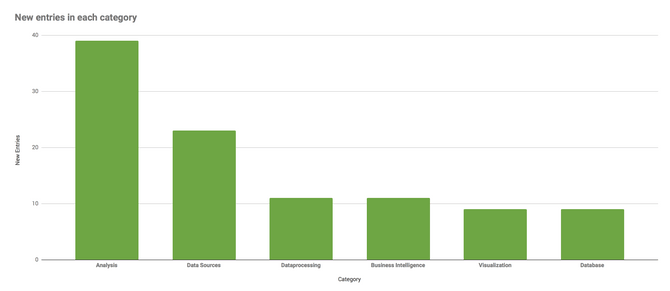
Furthermore, I would like to provide you with the questions that guided me in researching each area and the insights that I gathered in the year of maintaining this list. Below you see a little chart showing to which categories I have added the most tools in the last year.
Data Sources
One of the remaining questions, for us is what tools do offer good and legally compliant ways to capture user interaction? Instead of Google Analytics being the norm, we are always on the lookout for new and fresh solutions in this area. Despite Heatmap Analytics, another new category I added is «Tag Management˚ Regarding the classic website analytics solutions, I was quite surprised that there are still quite a lot of new solutions popping up. I added a whole lot of solutions, and entirely new categories like mobile analytics and app store analytics after discovering that great github awesome list of analytics solutions here.

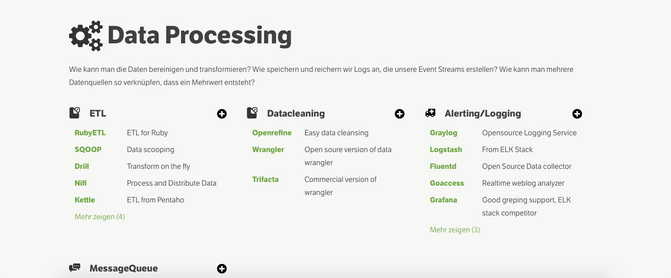
Data Processing
How can we initially clean or transform the data? How and where can we store logs that are created by these transformation events? And where do we also take additional valuable data? Here I’ve added quite a few of tools in the ETL area and in the message queue category. It looks like eventually I will need to split up the “message queue” category into multiple ones, because it feels like this one drawer in the kitchen where everything ends up in a big mess.
Database
What options are out there to store the data? How can we search through it? How can we access data sources efficiently? Here I mainly added a few specialized solutions, such as databases focused on storing mainly time series or graph/network data. I might either have missed something, but I feel that since there is no new paradigm shift on the horizon right now (like graph oriented, or nosql, column oriented or newsql dbs). It is probably in the area of big-data where most of the new tools emerged. An awesome list that goes beyond our collection can be found here.

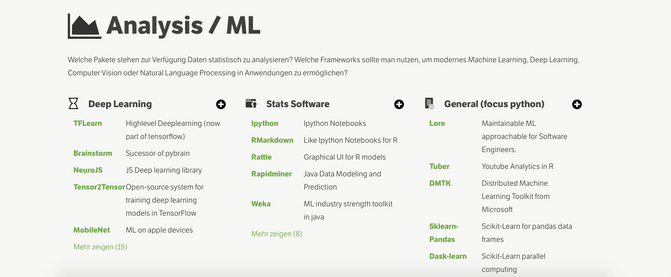
Analysis
Which stats packages are available to analyze the data? What frameworks are out there to do machine learning, deep learning, computer vision, natural language processing? Obviously, due to the high momentum of deep learning leads to many new entries in this category. In the “general” category I’ve added quite a few entries, showing that there is still a huge momentum in the various areas of machine learning beyond only deep learning. Interestingly I did not find any new stats software packages, probably hinting that the paradigm of these one size fits all solutions is over. The party is probably taking place in the cloud, where the big five have constantly added more and more specialized machine learning solutions. For example for text, speech, image, video or chatbot/assistant related tasks, just to name a few. At least those were the areas where I added most of the new tools. Going beyond the focus on python there is the awesome list that covers solutions for almost every programming language.
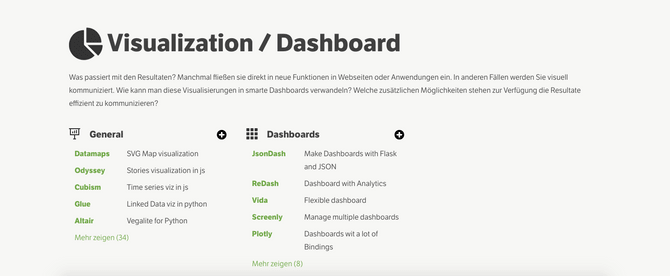
Visualization, Dashboards, and Applications
What happens with the results? What options do we have to visually communicate them? How do we turn those visualizations into dashboards or entire applications? Which additional ways of to communicate with user beside reports/emails are out there? Surprisingly I’ve only added a few new entries here, may it be due to the fact that I accidentally have been quite thorough at research this area last year, or simply because of the fact that somehow the time of js visualizations popping up left and right has cooled off a bit and the existing solutions are rather maturing. Yet this awesome list shows that development in this area is still far from cooling off.
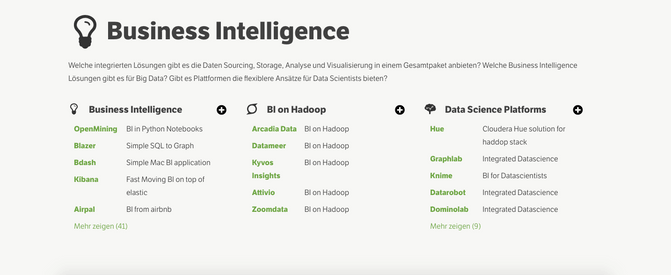
Business Intelligence
What solutions do exist that try to integrate data sourcing, data storage, analysis and visualization in one package? What BI solutions are out there for big data? Are there platforms/solutions that offer more of a flexible data-scientist approach (e.g. free choice of methods, models, transformations)? Here I have added solutions that were platforms in the cloud, it seems that it is only logical to offer less and less of desktop oriented BI solutions, due to the restrained computational power or due to the high complexity of maintaining BI systems on premise. Although business intelligence solutions are less community and open source driven as the other stacks, there are also awsome lists where people curate those solutions.
You might have noticed that I tried to slip in an awsome list on github into almost every category to encourage you to look more in depth into each area. If you want to spend days of your life discovering awesome things, I strongly suggest you to check out this collection of awesome lists here or here.
Conclusion or what's next?
I realized that keeping the list up to date in some areas seems almost impossible, while others gradually mature over time and the amount of new tools in those areas is easy to oversee. I also had to recognize that maintaining an exhaustive and always up to date list in those 5 broad categories seems quite a challenge. That's why I went out to get help. I’ve looked for people in our company interested particularly in one of these areas and nominated them technology ambassadors of this part of the stack. Their task will be to add new tools whenever they pop up on their horizon.
I have also come to the conclusion that the stack is quite useful when offering customers a bit of an overview at the beginning of a journey. It adds value to just know what popular solutions are out there and start digging around yourself. Yet separating more mature tools from the experimental ones or knowing which open source solutions have a good community behind it, is quite a hard task for somebody without experience. Somehow it would be great to highlight “the pareto principle” in this stack by pointing out to only a handful of solutions and saying you will be fine when you use those. Yet I also have to acknowledge that this will not replace a good consultation in the long run.
Already looking towards the improvement of this collection, I think that each tool needs some sort of scoring: While there could be plain vanilla tools that are mature and do the job, there are also the highly specialized very experimental tools that offers help in very niche area only. While this information is somewhat buried in my head, it would be good to make it explicit on the website. Here I am highly recommending what Thoughtworks has come up with in their technology radar. Although their radar goes well beyond our little domain of data services, it offers a great idea to differentiate tools. Namely into four categories:
- Adopt: We feel strongly that the industry should be adopting these items. We see them when appropriate on our projects.
- Trial: Worth pursuing. It is important to understand how to build up this capability. Enterprises should try this technology on a project that can handle the risk.
- Asses: Worth exploring with the goal of understanding how it will affect your enterprise.
- Hold: Proceed with caution.
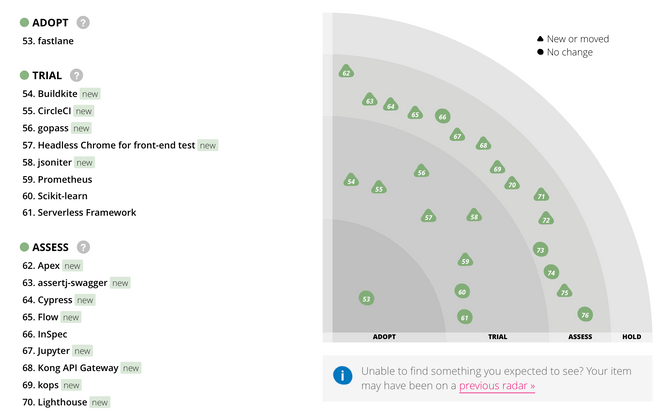
Assessing tools according to these criteria is no easy task - thoughtworks is doing it by nominating a high profile jury that vote regularly on these tools. With 4500 employees, I am sure that their assessment is a representative sample of the industry. For us and our stack, a first start would be to adopt this differentiation, fill it out myself and then get other liipers to vote on these categories. To a certain degree we have already started this task internally in our tech db, where each employee assessed a common feeling towards a tool.
Concluding this blogpost, I realized that the simple task of “just” having a list with relevant tools for each area seemed quite easy at the start. The more I think about it, and the more experience I collect in maintaining this list, the more realize that eventually such a list is growing into a knowledge and technology management system. While such systems have their benefits (e.g. in onboarding or quickly finding experts in an area) I feel that turning this list into one will be walking down this rabbit hole of which I might never re-emerge. Let’s see what the next year will bring.