

We’ve all witnessed the hype in 2016 when people started hunting pokemons in “real-life” with the app Pokémon GO . It was one of the apps with the fastest rise in user-base and for a while with a higher addiction rate than crack - correction: I mean candycrush. Comparing it to technologies like telephone or email, it only took it 19 days to reach 50 mio users, vs. 75 years for the telephone.
Connecting the real with the digital world
You might be wondering, why I am reminiscing about old apps, we have certainly all moved on since the Pokemon GO hype in 2016 and are doing other serious things now. True, but I think though that the idea of “collecting” virtual things that are bound to real-life locations was a great idea and that we want to build more of it in the future. That’s why Pokemon is the starting point fort this blogpost. In fact If you are young enough to have watched the pokemon series, you are probably familiar with the idea of the pokedex.

The idea
The pokedex was a small device that Ash (the main character) could use to lookup information about certain pokemons in the animated series. He used it now and then to lookup some facts about them. While we have seen how popular the pokemon GO was, by connecting the real with the digital world, why not take the idea of the pokedex and apply it in real world scenarios, or:
What if we had such an app to distinguish not pokemons but animals in the zoo?
The Zoo-Pokedex
Imagine a scenario where kids have an app their parent’s mobile phones - the zoo-pokedex. They start it up when entering a zoo and they then go exploring. When they are at a cage they point the phones camera at the cage and try to film the animal with it. The app recognizes which animal they are seeing and gives them additional information on it as a reward.
Instead of perceiving the zoo as a educational place where you have to go from cage to cage and observe the animal, absorb the info material you could send them out there and let them “capture” all the animals with their Zoo-Pokedex.

Let’s have a look at the classic ways of learning about animals in a zoo:
Reading a plaque in the zoo feels boring and dated
Reading an info booklet you got at the cashier feels even worse
Bringing your own book about animals might be fun, when comparing the pictures of animals in the book with the real ones, but there is no additional information
Having a QR code at the cage that you need to scan, will never feel exciting or fun
Having a list of animals in my app that I can tap on to get more info could be fun, but more for parents in order to appear smart before their kids giving them facts about the animal
Now imagine the zoo-pokedex, you really need to go exploring the zoo in order to get information. In cases where the animals area is big and it can retreat you need to wait in front of it to take a picture of it. That takes endurance and perseverance. It might even be the case that you don’t get to see it and have to come back. When the animal appears in front of you, you’ll need to be quick - maybe even an element of surprise, excitement is there - you need to get that one picture of the animal in order to check of the challenge. Speaking of challenge, why not make it a challenge to have seen every animal in the zoo? That would definitely mean you need to come back multiple times, take your time and go home having ticked off 4-5 animals in your visit. This experience encourages you to come back and try again next time. And each time you learn something, you go home with a sense of accomplishment.
That would definitely be quite interesting, but how could such a device work? Well we would definitively use the phone’s camera and we could train a deep learning network to recognize the animals that are present in the zoo.
So imagine a kid walking up to an area and then trying to spot the animal in order to point his mobile phone to it and then magically a green check-mark appears next to it. We could display some additional info material like where they are originally from, what they eat, when they sleep etc.., but definitely those infos would feel much more entertaining than just reading them off a boring info plaque.
How train the Pokedex to distinguish new animals
Well nice idea you say, but how am I going to make that magical device that will recognize animals, especially the “weird” ones e.g. the oryx in the title :) . The answer is …. of course …. deep learning.
In recent years you have probably noticed the rise of deep learning in different areas of machine learning and noticed their practical applications in your everyday life. In fact I have covered a couple of these practical applications such as state of the art sentiment detection or survival rates for structured data or automatic speech recognition and text to speech applications in our blog.
Deep learning image categorization task
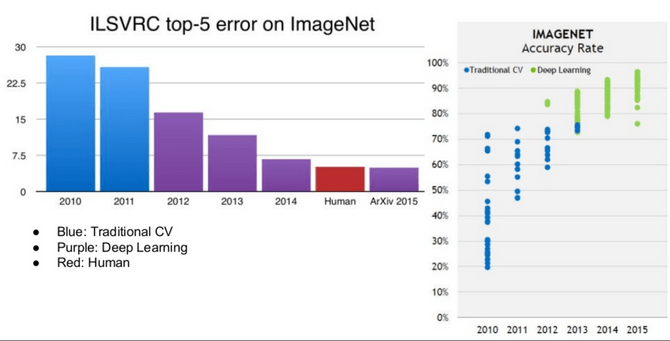
The area we need for our little zoo-pokedex is image categorization. Image categorization tasks have advanced tremendously in the last years, due to deep learning outperforming all other machine learning approaches (see below). One good indicator of this movement is the yearly imagenet competition, which is about letting machine learning algorithms compete about the best way of finding out what can be seen on an image. The task is simple: there are 1000 categories of everyday objects such as cats, elephants, tea-cattles and millions of images that need to be mapped to one of these categories. The algorithm that makes the lowest error wins. Below is an example of the output on the sample images. You’ll notice that the algorithm displays the label of which it thinks the image belongs to.

Now this ILSVRC competition has been going on for a couple of years now and while the improvements that have been made have been astonishing each year, in the last 5 years especially in 2012 and 2013 deep learning appeared with a big bang on the horizon. As you can see on the image below the amount of state of the art solutions exploded and outperformed all other solutions in this area. It even goes so far that the ability of the algorithm to tell the contents apart is better than this of a competing human group. This super-human ability of deep learning networks in these areas is what the hype is all about.
How does it work?
In this blog post I don’t want to be technical but just show you how two easy concepts of convolution (kernels) and pooling are applied in a smart way to really achieve outstanding results in image recognition tasks with deep learning. I don’t want to go into details how deep learning works in the way of how it learns in the form of updating of weights, backpropagation but abstract all of this stuff away from you. In fact if you have 20 minutes and are a visual learner I definitely recommend that video below that does an extremely good job at explaining the concepts behind it:
Instead I will quickly cover the two basic tricks that are used to make things really work.
We’ll start by looking at a common representation of a deep learning network above and you’ll notice that two words appear a lot there, namely convolution and pooling. While it seems obvious that the image data has to travel through these layers from left to right, it would be cool if we only knew what these layers do.
Convolutions and Kernels
If you are not a native speaker you’ve probably have never heard of the word convolution before and might be quite puzzled when you hear it. For me it also sounded like some magic procedure that apparently does something very complicated and apparently makes the deep learning work :).
After getting into the field I realized that it's basically its an image transformation that is almost 20 years old (e.g. Computer Vision. From Prentice Hall book by Shapiro) and present in your everyday image editing software. Things like sharpening an image or blurring it, or finding edges are basically a convolution. It's a process of applying a small e.g. 3x3 Matrix over each pixel of your image and multiply this value with the neighbouring pixels and then collect the results of that manipulation in a new image.
To make this concept more understandable I stole some examples of how a 3x3 matrix, also called a kernel, transforms an image after being applied to every pixel in your image.
In the image below the kernel gives you the top-edges in your image. The numbers in the grey boxes represent the gray image values (from 0 black to 255 white) and the little numbers after the X represent how these numbers are multiplied when added together. If you change these numbers you get another transformation.

Here is another set of numbers in the 3x3 matrix that will blur your image.

Now normally the way of create such “filters” is to hand-tune these numbers by hand to achieve the desired results. With some logical thinking you can easily come up with filters that sharpen or blur an image and then apply those to the image. But how are these applied in the context of deep learning?
With deep learning we do things the other way round, we teach the neural network to find filters that are somewhat useful in regards to the final result. So for example to tell a zebra apart from an elephant it would really be useful if we had a filter that detects diagonal edges. And if the image has diagonal edges e.g. the stripes of the zebra, it's probably not an elephant. So we train the network on our training images of zebras and elephants and let it learn these filters or kernels on its own. If the emerging kernels are helpful with the task they have a tendency to stay, if not, they keep on updating themselves until they become useful.
So one layer that applies such filters or kernels or convolutions is called a convolutional layer. And now comes another cool property. If you keep on stacking such layers on top of each other, each of these layers will find own filters that are helpful. And on top of that each of these filters will become more and more complicated and be able to detect more detailed features.

In the image above (which is from a seminal paper, you see gray boxes and images. A great way to show these filters is to show the activations or convolutions which are these gray boxes. The images are samples that “trigger” these filters the most. Or said the other way round, these are images that these filters detect well.
So for example in the first layer you’ll notice that the network detects mostly vertical, horizontal and diagonal edges. In the second layer its already a bit “smarter” and is able to detect round things, e.g. eyes or corners of frames etc.. In the third layer its already a bit smarter and is able to detect not only round things but things that look like car tires for example. This layering often goes on and on for many layers. Some networks have over 200 of these layers. That's why they are called deep. Now you know. So usually adding more and more of these layers makes the network better at detecting things but also it makes it slower and sometimes less able to generalize for things it had not seen yet.
Pooling
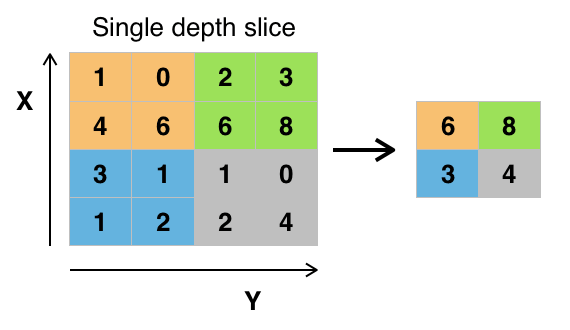
The second word that you might see a lot in those architecture above is the word pooling. Here the trick is really simple: You look at a couple of pixels next to each other e.g. 2x2 and simply take the biggest value - also called max-pooling. In the image below this trick has been applied for each colored 2x2 area and the output is a much smaller image. Now why are we doing this?
The answer is simple, in order to be size invariant. We try to scale the image down and up multiple times in order to be able to detect a zebra that is really close to the camera vs. one that might only be viewable in the far distance.
Putting things together
After the small excursion into the two main principles of inner workings of state of the art deep learning networks we have to ask the question of how we are going to use these tricks to detect our animals in the zoo.
While a few years ago you would have had to write a lot of code and hire a whole machine team to do this task, today you can already stand on the shoulders of giants. Thanks to the Imagenet competitions (and I guess thanks to Google, Microsoft and other research teams constantly outputting new research) we can use some of these pretrained networks to do our job for us. What does this mean?
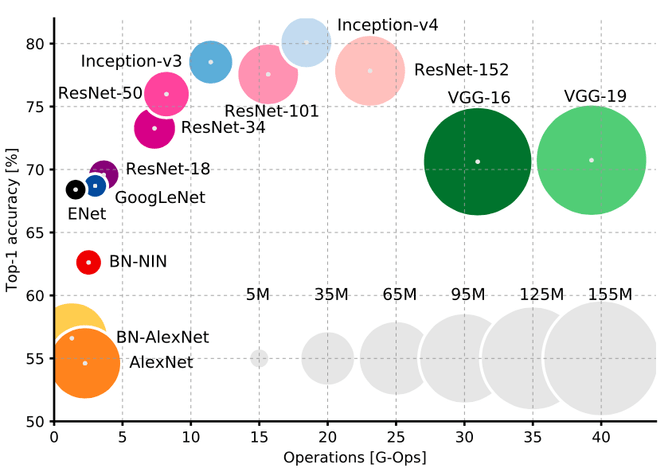
The networks that are often used in these competitions can be obtained freely (In fact they even come https://github.com/pytorch/pytorch pre-bundled to the deep-learning frameworks) and you can use networks these without any tuning in order to be able to categorize your image into the 1000 categories that are used in the competition. As you can see in the image below the bigger in terms of layers the network the better it performs, but also the slower it is and the more data it needs to be trained.
Outlook - Part 2 How to train state of the art image recognition networks to categorize new material
The cool thing now is that in the next blog post we will use these pretrained networks and teach them new tricks. In our case teach them to tell apart a llama from an oryx, for our zoo pokedex. So basically train these network to recognize things these networks have never been trained to do. So obviously we will need training data and we have to find a way to somehow teach them new stuff without “destroying” their properties of being really good at detecting common things.
Finally after that blog post I hope to leave you with at least one the takeaway of demystifying deep learning networks in the image recognition domain. So hopefully whenever you see these weird architecture drawings of image recognition deep learning networks and you see those steps saying “convolution” and “pooling” you’ll hopefully know that this magic sauce is not that magic after all. It’s just a very smart way of applying those very old techniques to achieve outstanding results.