
Migros possède plusieurs sites web et une application mobile, qui nécessitent tous d’afficher des données produits. Nous avons développé M-API, une application Symfony qui récupère les données des différents systèmes, les nettoie et les indexe dans Elasticsearch. Cet index peut être consulté en temps réel via une API REST, avec des réponses en JSON et XML. La M-API gère plusieurs millions de requêtes par jour, et fonctionne même lors des pics de trafic.
Architecture de l'API
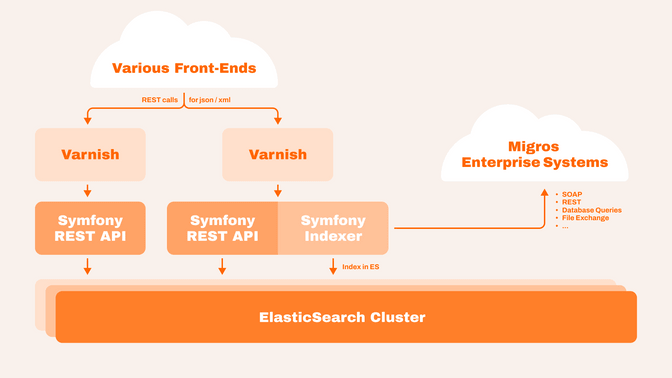
Les documents Elasticsearch sont volumineux et contiennent de nombreuses données imbriquées. Nous avons décidé de dénormaliser toutes les données produits directement dans chaque document produit pour accélérer les recherches. Lorsque n’importe quelle partie des informations d’un produit change, nous reconstruisons les données et ré-indexons le produit. L’API offre des paramètres de requête permettant aux clients de contrôler le niveau de détail souhaité.
L’application Symfony est conçue autour de modèles de domaine représentant les données. Lors de l’indexation, les modèles sont remplis avec les données des systèmes externes, puis sérialisés dans Elasticsearch. Lors des requêtes, les modèles sont restaurés à partir des réponses d’Elasticsearch, puis re-sérialisés dans le format demandé avec le niveau de détail souhaité.
Nous utilisons JMS Serializer, qui permet de grouper les champs pour ajuster le niveau de détail et gérer plusieurs versions d’API à partir d’une seule source de données. Pour améliorer les performances, nous avons développé notre propre sérialiseur pour JMS.
Il y a bien sûr un coût en performance dû à la désérialisation et re-sérialisation des données Elasticsearch, mais la flexibilité obtenue compense largement ce coût.
Au niveau frontend, nous utilisons des serveurs Varnish pour mettre en cache les réponses. Nous nous appuyons sur FOSHttpCacheBundle pour gérer les en-têtes de cache et invalider les données lorsque c’est nécessaire.
Une API indépendante
La M-API est une application Symfony autonome, qui ne génère pas de rendu HTML. Son seul objectif est de collecter, normaliser et indexer les données, puis de les fournir via une API REST. Cela permet de développer différentes plateformes qui exploitent les mêmes données.
Les systèmes qui utilisent la M-API incluent un site de catalogue produit, une application mobile, une plateforme communautaire pour les clients et divers sites marketing dédiés à des gammes de produits spécifiques. Chaque plateforme peut être développée indépendamment, avec des technologies différentes de PHP. Alors que le catalogue de produits a été mis en œuvre comme une application Symfony, l'app mobile est une application native IOS et Android, et de nombreux sites de marketing sont réalisés avec le CMS Magnolia basé sur Java.

Grâce à la M-API, ces applications web peuvent se concentrer sur leur utilisation principale, sans avoir à réimplémenter des systèmes d’importation de données depuis différentes sources. Cela réduit l’effort et le temps de développement, tout en améliorant la qualité des données, car les corrections et améliorations sont centralisées dans la M-API.
La gestion des données dans est plutôt complexe. La M-API collecte:
- les données de base des produits provenant du catalogue central des produits et des systèmes de prix
- les images préparées pour le web via le CDN rokka.io
- Métadonnées telles que les avertissements chimiques ou les recommandations de produits provenant d'analyses de data warehouse
- les informations sur les stocks provenant du système de gestion des stocks ainsi qu'une recherche de magasin
- les données de popularité basées sur les commentaires des clients et Google Analytics
Processus de développement
Avec le client, nous avons choisi un processus agile. Le minimum viable product (MVP) était une API fournissant des données produits en JSON et XML. Après quelques mois, l’API a atteint un niveau de fonctionnalité suffisant et a été mise en ligne. Au cours des 10 dernières années, nous avons ajouté de nouvelles sources de données et de nouveaux endpoints API, avec des releases toutes les deux semaines.
Pour garantir une API stable, nous avons mis en place une versioning d’API. Chaque requête doit inclure un en-tête indiquant la version. Cela permet aux client·e·s de mettre à jour à leur propre rythme. Grâce au JMS Serializer, nous avons pu adapter les formats de données sans dupliquer les données. Nous avons également tenu un changelog pour aider les client·e·s à suivre les évolutions
Pour déployer de nouvelles fonctionnalités sans les exposer prématurément, nous avons utilisé des feature flags.
Architecture d’indexation
Lors de l’indexation, nous dénormalisons une grande quantité de données pour optimiser la vitesse des requêtes. Par exemple, nous stockons l’intégralité du breadcrumb des catégories produit directement dans chaque document produit, pour éviter d’avoir à exécuter plusieurs requêtes Elasticsearch.
Pour gérer ce volume de données, nous avons copié les données lentes à interroger dans une base MySQL locale, servant essentiellement de cache. Nous avons aussi utilisé Redis pour stocker les données intermédiaires, accélérant encore le processus. Enfin, nous avons séparé le processus en deux étapes : collecte des données puis indexation. Elasticsearch fonctionne en cluster avec plusieurs nœuds, car l’indexation impose une forte charge sur le système.
Le processus d’importation des données exécute des commandes Symfony qui mettent à jour la base MySQL. Ces opérations sont parallélisées à l’aide de RabbitMQ. Une fois la file de messages vide, l’indexation Elasticsearch commence également en mode parallèle.
Un défi majeur était la gestion des changements de schéma Elasticsearch. L’index contient des centaines de milliers de documents, reconstruire un index complet prend donc du temps.
Pour optimiser cela:
- le nouveau code est déployé sans être mis en ligne
- un nouvel index est créé en copiant les documents de l'ancien index (plus rapide qu'une réimportation complète)
- une fois terminé, le nouvel index est activé.
Cette stratégie permet d'économiser temps et ressources système.